次にこれまでの経緯を見ていこう。グリッドの源流をたどると,90年代初めにスタートした米国の「情報スーパーハイウエイ構想」に行き当たる。米政府は,その一環として「高性能コンピューティング&コミュニケーション(HPCC)計画」注3)を推し進め,ネットワークに関係する研究に厚く予算を配分するようになった。
そのため公的な研究機関はこぞって,スーパーコンピュータを相互接続するなどして高速処理を実行するプロジェクトを打ち出した。その後も研究熱は高まり,一部の研究者の間が「グリッド・コンピューティング」という言葉を使い始める。
この動きと並行して,95年ごろからインターネットが爆発的に普及し始めた。自然と接続すべき対象に一般家庭のパソコンが加わるようになり,グリッドに関する実験的なプロジェクトがいくつも立ち上がった。
第一幕は研究機関が主役
これがグリッドの“第一幕”である。推進者の中心は公的な研究機関だ。99年には前出のSETI@homeが始まったのに加えて,ディストリビュート・ネットという団体が約10万台のコンピュータを接続した高速処理によって,強固な暗号を解読したことが話題を呼んだ。
2001年になると,英国ナショナル・e-サイエンス・センターの「e-サイエンス」,全米科学財団(NSF)の「テラグリッド」,欧州合同原子核研究機関(CERN)の「データグリッド」といったグリッドの超大型プロジェクトが相次いで発表された。
当然のことながら,これらのプロジェクトは単にコンピュータを相互接続するだけではない。協調分散処理や,広域かつ大容量のデータ共有,セキュリティなどの研究が行われている。例えばCERNでは,素粒子の解析のために1年間に数ペタバイト(ペタは10の15乗)のデータを処理する必要がある。これを世界各地のスーパーコンピュータで分散処理するため,大量のデータを分散配置し,共有する研究を行っている。
とはいえ,ここまでなら科学技術計算というごく狭い分野の話。夢はあるが,コンピュータ・メーカーがこぞって実用化を競うほどにはならないはずだった。
Webサービスを統合
転機が訪れたのは2001年のこと。米IBMが,グリッド・コンピューティングに関する草分け的な研究開発組織である「グローバス・プロジェクト」と提携し,互いの技術を持ち寄って,従来に比べて大幅に拡張したグリッド・コンピューティングの技術仕様を共同で開発したのだ。
両社は2002年2月に,これを国際標準とすべく「OGSA(Open Grid Services Architecture)」と名付けて公開した。このあたりからが現在に続く“第二幕”の始まりである。
一体なぜIBMはグリッドに目を付けたのか。以前から同社は,コンピュータが自律的に再構成や修復,防御などを行う「Autonomic Computing」注4)と呼ぶ仕組みの研究開発を続けてきた。そうした中で並列処理,協調処理を行うグリッドが,「その重要な技術になると考えた」(日本IBMの野村部長)のが理由だ。
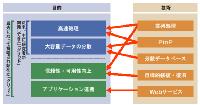 図3 グリッド・コンピューティングの意味するところは2段階ある [画像のクリックで拡大表示] |
一方,OGSAが発表される前から,研究者の間でグリッドの応用範囲を広げようとする動きもあった。「基になったのは『処理能力は一種の“サービス”であり,記憶装置やデータ,さらにはアプリケーションも同様。それらの“サービス”をいつでも,どこからでも利用できるようにしよう』という発想だった」(グリッド協議会の関口会長)。
この流れの中で,従来の並列処理や分散データベースといった技術に加え,PtoP(Peer to Peer)やWebサービスなどインターネットに関連する様々な技術がグリッドの構成要素(研究対象)と見なされるようになる(図3[拡大表示])。こうしてグリッドが一躍,情報システムの「次世代基盤」に祭り上げられた。



















































