第1回はXMLを利用した一例としてRSSデータを紹介した。今回は前回の例(アップルコンピュータが公開しているトップテンソングRSSデータ)にちなみ,簡単な音楽情報をXMLデータとして電子データ化する過程を追いながら,XMLの特徴を解説していく。
■ 情報の電子データ化,まずはCSV
例えば表1のような音楽情報(解説のための例として2曲分とした)があるとしよう。
表1 サンプルとして使う音楽情報
| アーティスト名 | 画像ファイル名 | 画像の幅 | ソング名 |
| BoA | ufkzowir.jpg | 53 | 七色の明日 |
| 上木彩矢 | xncpgduc.jpg | 53 | ピエロ |
これらを電子データ化するとしよう。テキストによるデータ形式の代表的なものとしてCSV形式がある。まずはこれらの情報をCSV形式でデータ化する。すると次のようになる。ただし,ここから先は「アーティスト名」を「artist」,「画像ファイル名」を「coverArt」,「画像の幅」を「width」,「ソング名」を「song」の項目名で扱う。
artist,coverArt,width,song BoA,ufkzowir.jpg,53,七色の明日 上木彩矢,xncpgduc.jpg,53,ピエロ
■ データのXML化
そしてこれをXML形式に書き直すと,「こんな感じ」になる(この記述はまだ正式なXMLドキュメントではない)。<artist>BoA</artist><coverArt>ufkzowir.jpg</coverArt>・・・ <artist>上木彩矢</artist><coverArt>xncpgduc.jpg</coverArt>・・・
XMLではタグを用い,データをマークアップしていく。CSVでの項目名が,XMLでのタグ名になるわけである。artist項目をartist要素として,coverArt項目をcoverArt要素として表現する。XMLでは,要素名のアルファベットの大文字と小文字を区別するため,開始タグと終了タグのアルファベットの大文字と小文字を必ず合わせておく必要がある。ここでは使用していないが,XMLでは要素名として漢字やひらがなを使用することもできる。
CSVでは改行が1レコード分の区切りとなっているが,XMLではそのようなルールがない。上記の記述では確かに2行で記述されているが,XML的には1行で記述されていることと同等なのである。厳密には2行の記述と1行の記述では改行の有無に違いがあり,その点でXMLとしてもまったくのイコールというわけではない。しかし一般的なXML処理の過程においては,同等なものとして扱われる。したがって,XMLでは1レコード分の区切りを示す部分で改めてタグを使用する。1レコード分の区切りとして,例えばitemタグを追加すると,以下のようになる。
<item><artist>BoA</artist><coverArt>ufkzowir.jpg</coverArt>・・・ <item><artist>上木彩矢</artist><coverArt>xncpgduc.jpg</coverArt>・・・
前述のように,一般的なXML処理においては改行やタブや半角空白などのインデントを無視できる。このため上記を以下のように記述しても同等である。
<item> <artist>BoA</artist> <coverArt>ufkzowir.jpg</coverArt> <width>53</width> <song>七色の明日</song> </item> <item> <artist>上木彩矢</artist> <coverArt>xncpgduc.jpg</coverArt> <width>53</width> <song>ピエロ</song> </item>
これはXMLとしてよく見る形ではないだろうか。XMLは,人が見てわかりやすいという特徴がある。そして同時に,プログラムから扱うことができるデータ形式である。
最後に,XMLのルールではXMLのルート要素は必ず1つなければならない。上記の記述では,ルートの位置に2つのitem要素が存在している。こういう場合も,もう一度タグを追加する。ルート要素名を例えばrssとすると,以下のようになる。これで一つのXMLドキュメントが出来た。
<rss>
<item>
<artist>BoA</artist>
<coverArt>ufkzowir.jpg</coverArt>
<width>53</width>
<song>七色の明日</song>
</item>
<item>
<artist>上木彩矢</artist>
<coverArt>xncpgduc.jpg</coverArt>
<width>53</width>
<song>ピエロ</song>
</item>
</rss>
■ 要素と属性
ここまでで,所定の情報を電子データ化するという目的は達成できたが,XMLの場合はここでもう少しの工夫ができる。上記XMLドキュメントでは,artistやcoverArtなどと並列にwidth項目が記述されているため,これらが互いに独立した項目であるように見える。しかしwidth項目は,coverArt項目に従属したデータであり,独立した一つの項目とはいえない。つまりwidthは,coverArt項目のプロパティのような位置づけである。XMLではこのような項目を属性として表現することができる。そうするには上記XMLドキュメントを以下のように変更する。こちらの方が,各項目の関係性をうまく表現できている。
<rss>
<item>
<artist>BoA</artist>
<coverArt width="53">ufkzowir.jpg</coverArt>
<song>七色の明日</song>
</item>
<item>
<artist>上木彩矢</artist>
<coverArt width="53">xncpgduc.jpg</coverArt>
<song>ピエロ</song>
</item>
</rss>
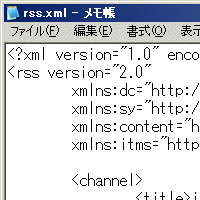 図 アップルコンピュータが提供していRSSデータ [画像のクリックで拡大表示] |
■ XML応用言語
これだけが情報項目のすべてであれば,わざわざXMLにする必要もないかもしれない。しかし実際にアップルコンピュータが提供しているRSSデータ(本連載第1回の図3)は,さらに多くの情報項目を持っている。そして各情報項目は,要素や属性として巧みに構成されたものである。これまで見てきたように,XMLによる記述はCSVと比べると格段に記述量が多くなる。それゆえXMLは冗長であると言われることもあるが,XMLの要素と属性,そして名前空間を使用した表現は,CSVでは実現できない高機能性を提供してくれる。そしてさまざまなことを考慮した結果,標準的にまとめられた一つのタグセットが「RSS 2.0」であり,アップルコンピュータが公開しているトップテンソングのRSSデータは,RSS 2.0形式で提供されている。厳密にはRSS 2.0をベースとした拡張形式といえるが,どこが拡張部分であるかは名前空間の理解が必要になるので,また次回以降に解説する。XMLを使用すると,要素の階層構造と属性と名前空間を用いて新しいタグセットを構成することができる。何らかの団体やコミュニティがまとめた,ある程度大規模な標準的なタグセットのことを一般にXML応用言語などと呼ぶ。XMLにより,さまざまな新しい応用言語を作成することができるわけだ。
次回は,XMLの文法の中でも最初に押さえておきたい基本的な項目を,いくつか解説してみる。
|
木村 達哉 インフォテリア 教育部 インフォテリア認定教育センターの運営や,XML技術者認定制度のXMLマスターに対応したコーステキストの開発などに携わる。XMLは,何となく知っているようでもそれを正しく扱うためにはなかなか奥が深いもの。そんなXMLへの入口を紹介します。 |



















































