 写真5 wcの利用例 Vine Linux 3.2の「.canna」を調べた例です。最初の「191」は行数,次の「631」は単語数,「5536」はバイト数を表しています。 [画像のクリックで拡大表示] |
 図2 dfの実行例 [画像のクリックで拡大表示] |
 図3 特定のマウント・ポイントの情報だけを表示する例 [画像のクリックで拡大表示] |
●tr
tr*11は,標準入力から渡された文字の変換や削除,連続する文字の圧縮を行い,標準出力に渡すコマンドです。
trコマンドのもっともシンプルな形式は,第1引数で指定した文字を抽出し,第2引数で指定した文字に変換することです。以下の例では,英小文字a~cが英大文字A~Cに変換されます。

ここで,trコマンドは「文字列」ではなく,「文字」を変換することに注意しましょう。
文字を削除したい場合には「-d」オプションを指定します。例えば,英小文字a~cを削除するには,

と入力します。trコマンドでも正規表現が使えます。
連続する文字を圧縮するには,「-s」オプションを指定します。例えば,英小文字eが連続している文字列を圧縮し,英小文字eの1文字にするには,

と入力します。
●cut
cutはテキスト・ファイルの各行から指定した部分を取り出すコマンドです*12。
指定する部分には,バイト(-bオプション),文字(-cオプション),フィールド(-fオプション)が使えます。例えば,1文字目から10文字目といった範囲指定は「-c 1-10」となりますし,4文字目以降すべてを取り出す場合には「-c 4-」と指定します。一般に各行の文字数は固定ではありませんので,始めの文字位置だけを指定し,終わりの文字位置は指定しません。

●uniq
uniqはテキスト・ファイルで重複している行を取り除くコマンドです*13。ただし,事前にテキスト・ファイルをソート(整列)しておく必要があります。デフォルトの出力先は標準出力です。sortコマンドと組み合わせて使うことが一般的です。
例えば,sample.text内の重複行を取り除き,標準出力に渡すには,

と入力します。
●wc
wc*14は,テキスト・ファイルの行数,単語数,バイト数を標準出力に渡すコマンドです*15。ここで,「単語」とは空白文字やタブ文字で区切られた長さが0でない文字列のことです。
例えば,テキスト・ファイルsample.textでは以下のような結果になります。

ここで,最初の「26」は行数,次の「26」は単語数,「52」はバイト数です。
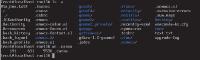
wcコマンドでは,行数(-lオプション),単語数(-wオプション),バイト数(-cオプション)を指定して出力することもできます。また,Vine Linux 3.2の「.canna」を調べた場合を写真5[拡大表示]に示します。
●duとdf
du*16は,ファイルのディスク使用量を表示するコマンドです。一方のdfは*17,ファイル・システムのディスク使用状況を表示するコマンドです。
例えば,ユーザーjunのホーム・ディレクトリ全体の使用量を調べるには,

と入力します。-sオプションを指定しないと,ホーム・ディレクトリ下の各ファイルおよびサブディレクトリごとの使用量が表示されます。表示される数値の単位はKバイトです。この例では,ユーザーjunのホーム・ディレクトリ全体のサイズが,104Kバイトであることが分かります。ちなみに「-m」オプションを指定すると,Mバイト単位となります。
dfコマンドを引数なしで実行すると,すべてのファイル・システムの使用状況を表示します(図2[拡大表示])。この例では,ハード・ディスクに3つのパーティションがあり,/(ルート),/home,/usrディレクトリがマウントされています。ホーム・ディレクトリのマウント・ポイント(/home)の容量については4%しか使用しておらず,未使用領域は十分に残っていることが分かります。/dev/shmは仮想メモリー・ベースのRAMディスクです。
特定のマウント・ポイントだけを表示することもできます。例えば/homeを表示するには,図3[拡大表示]のように入力します。



















































