Hadoopの高速性をひも解くとき、分散ファイルシステム「HDFS」の存在は欠かせない。MapReduceと協調して行う“ローカル処理”は、バッチ処理の高速化に向くアーキテクチャーだ。そんなHDFSにも、BIツールなどが使いづらいという課題がある。HDFSの代替製品をHadoopに組み込む動きは、その解決を目指すものだ。
「HDFS(Hadoop Distributed File System)」は、その名の通り分散バッチ処理ソフト「Apache Hadoop」向けのファイルシステムだ。ファイルを分割して複数のディスクで管理、大量データ処理のスループットを引き上げる。最近になり、HDFSの課題を解決しようと、代替製品をHadoopに組み込む例が増えてきた。
HDFSが大量データを効率よく処理するための工夫は、大きく二つある。一つは、データを複数のディスクから並行して読み、処理の多重度を上げることだ。「テラバイト級のデータを読み込むには、ディスクの単体性能を上げても追いつかない。そこで、数多くのディスクを並べ、そこから同時に読み出そうと考えた」。NTTデータ 基盤システム事業本部 シニアエキスパートの濱野賢一朗氏は、HDFSの狙いをこう話す。
HDFSは、DataNodeとNameNodeの二つの構成要素から成る。ファイルは一定サイズのブロック(デフォルトは64Mバイト)に分割し、DataNodeが管理するディスクに格納する。各ブロックを多重化(デフォルトで3重化)して保存することで、ディスク障害などに備えている(図1)。
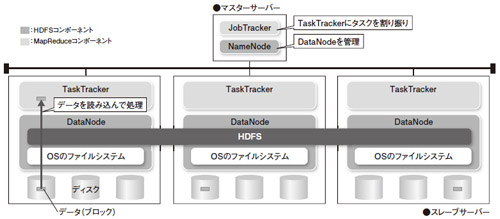
図1●HDFSはデータをブロック単位に格納
HDFSは、複数のDataNodeにまたがる形でデータを格納。NameNodeがファイル名やブロックの位置情報などを管理する
[画像のクリックで拡大表示]